
The Beauty of Quality Data
This is a write-up of a talk I originally gave at the Open Data Institute in London on 22nd March 2016 on how we can improve open data quality, and why we must.
We have more open data than ever before, and most of it is really useful. A lot of it quite hard to use, and some of it is completely useless. Government policy in the UK has been fantastically successful in opening up datasets that were previously inaccessible to the public. The biggest issue we now face as consumers of that data is not quantity, but quality.
As the founder of Dataseed (an open data visualisation tool) I’ve had a lot of conversations with users who are struggling to make sense of open datasets. Usually they are struggling because the data is in a spreadsheet that has been formatted in a bizarre way, and they simply don’t have the ability to transform it into a workable shape.
In this article I’ll expose some of the most common spreadsheet anti-patterns that we see, and I’ll try to highlight the positive work that’s being done to improve the situation. First, let’s take a look at how things could be:
As good as it gets, for now
Imagine that we’re a small business and we’ve heard about the G-cloud procurement framework — designed to make it easier for government departments to buy from SME suppliers. We want to find out about who’s selling on the G-cloud framework and investigate whether it might be appropriate for us to sign up.
The first thing we do is Google for “gcloud statistics” and the first search result is this page that provides a list of downloadable CSV files. The first CSV file contains all the data up to the last month, so we open it up and it looks like this:
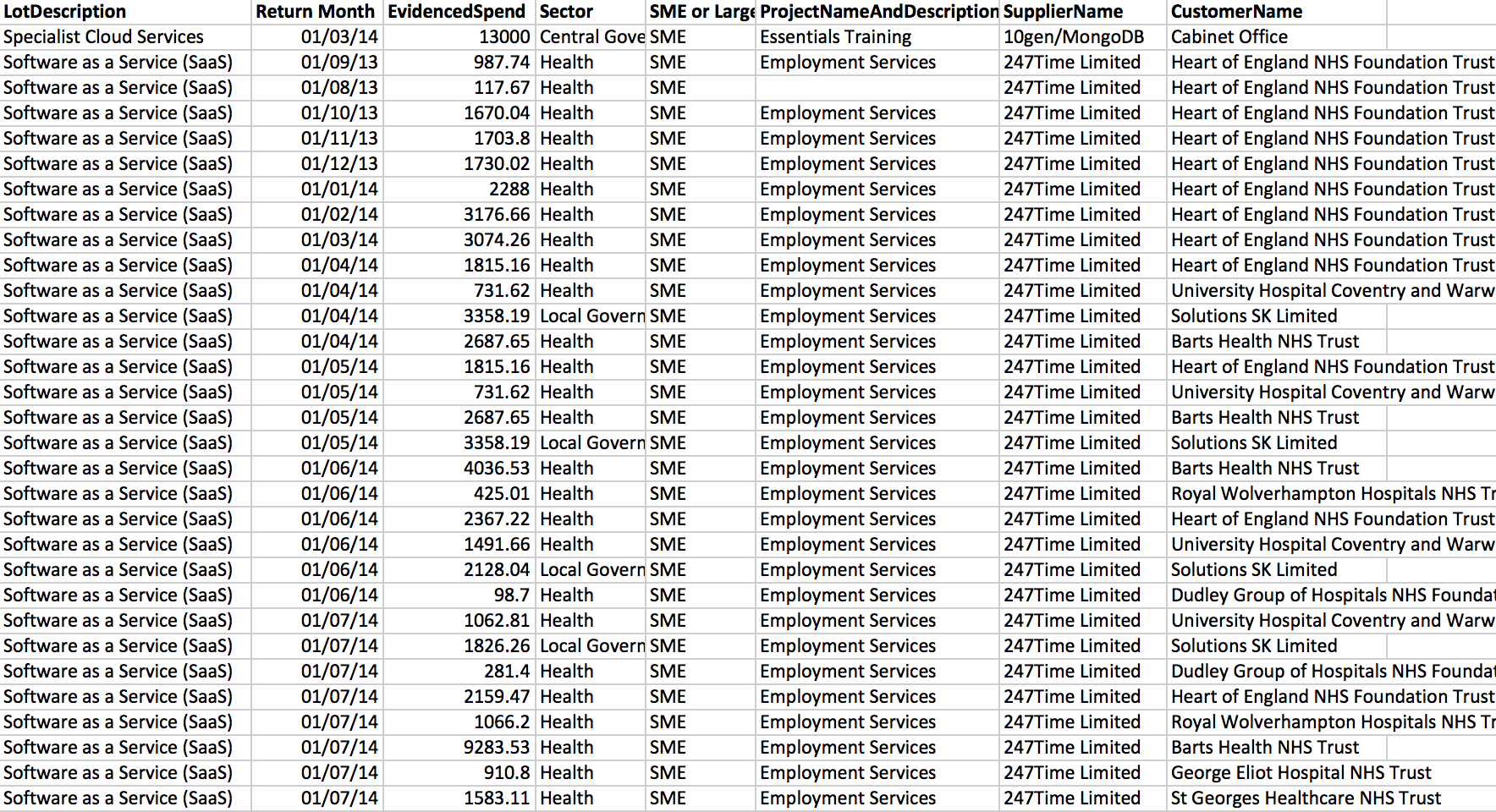
The format of this spreadsheet looks sane, but it has over 70,000 rows of transactions so we’re going to need some help to analyse it. We can just drag and drop the file into some interactive data visualisation software (we’ll use Dataseed) and within a couple of minutes we have a dashboard where we can visually explore the dataset.
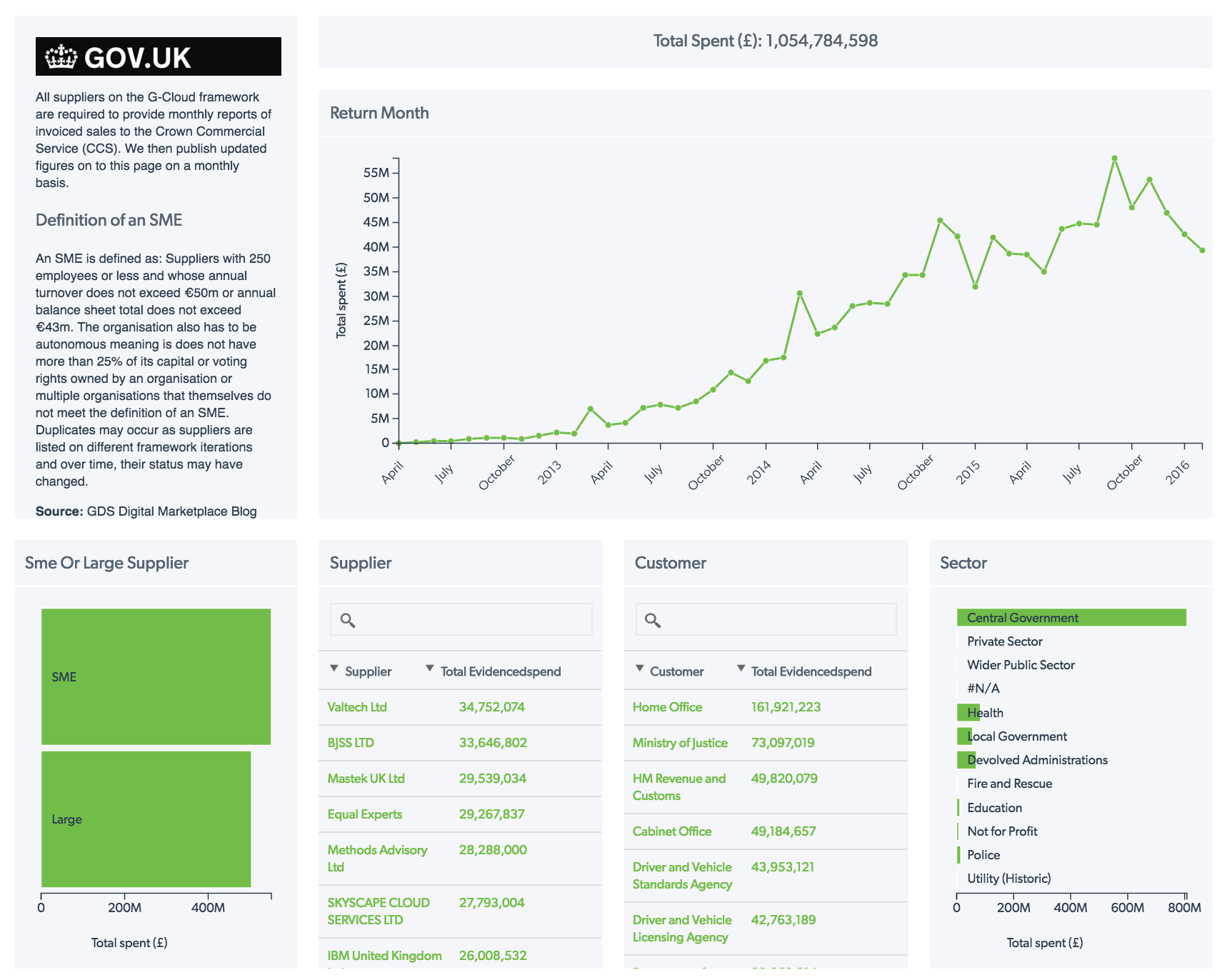
Dataseed visualisation of G-cloud data Interactive version
Now we can simply click on a “SME” to filter down on all the SME suppliers, perhaps we’ll also filter down on some of our competitors and see who their customers are, or we could explore the spending trends of different sectors.
This is about as good as it gets at the current point in time. It’s been easy to find the data, and easy to explore it with the help of some free tools. However, we need to ask ourselves some questions before we make any decisions based on this visualisation, these might include the following:
- Is there any missing data?
- How was the data collected?
- What is the definition of these terms, e.g. “SME”
- What is the license, how can I re-use this data?
These are all questions about the “data quality”.
What else do we mean by data quality?
This is debatable and there is no widely accepted definition. I would suggest that data quality includes issues such as accuracy, availability, completeness, consistency, machine-readability, and provenance.
The ODI did some research into the challenges for companies making use of open data. This is what companies said when they were asked to rate how much 8 issues affect their use of open data:
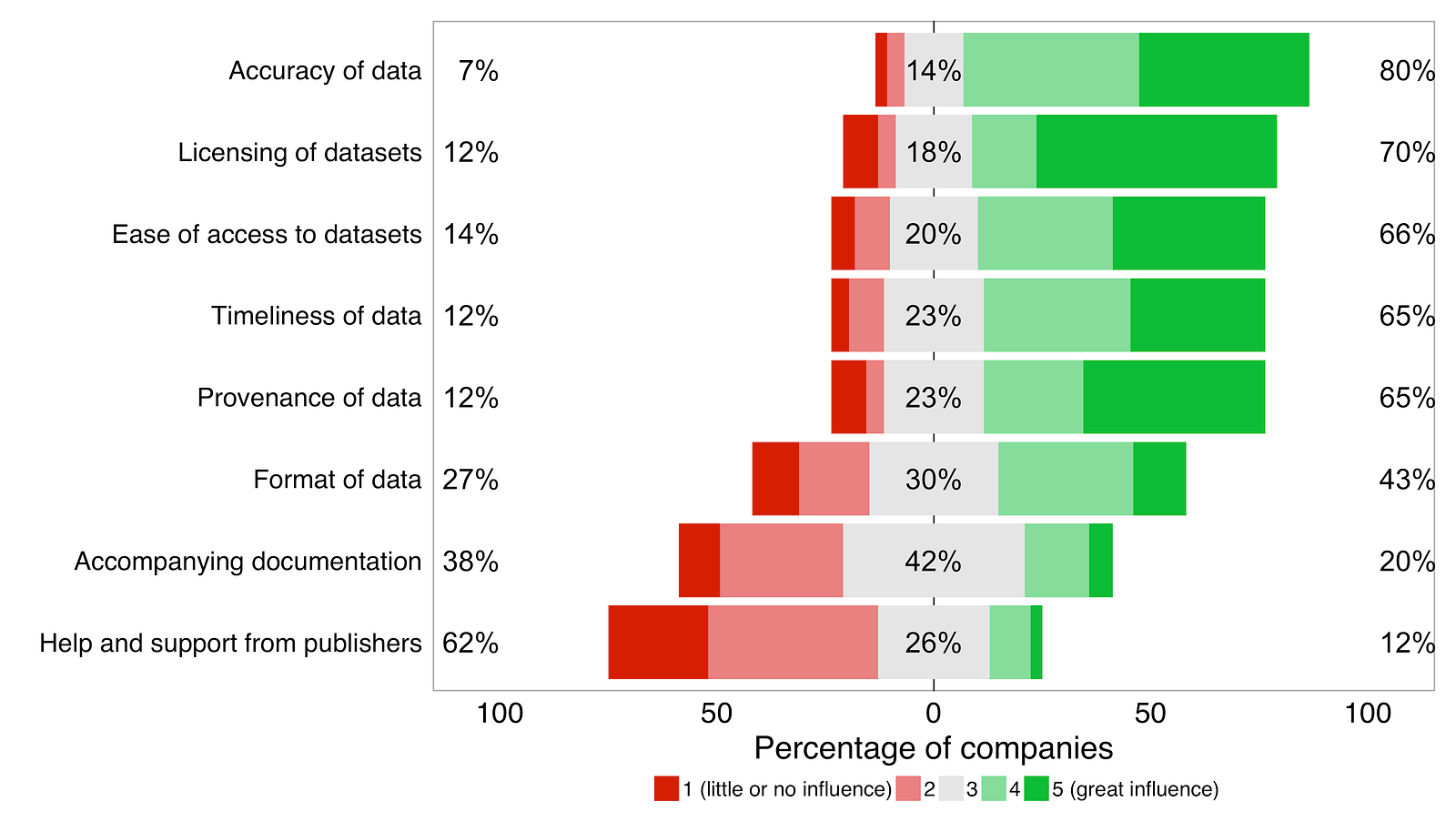
Responses to the question “Please indicate the extent to which each of the following issues influence your company’s decision to use open data.” (n=74). Source
These are all important issues, but for this article I’m only going to focus on the “format of data” and in particular how “machine-readable” it is.
This is why we can’t have nice things
Why can’t we always just go from a Google search to an interactive visualisation with all the accompanying information we need to interpret the data within a few minutes? In a word — spreadsheets.
Spreadsheets are a 2D grid that happily accepts the most heinous of formatting crimes. Everybody understands them though, and for that reason they are brilliant. We just need to agree on some ground rules if we’re to allow this permissive structure to stand between us and our precious data.
For your horror and amazement, here are some of the spreadsheet anti-patterns that I see Dataseed customers struggling with most often:
- Full dataset is spread over multiple files. This often happens when there is a file for each year, or for each geographical region. Typically you have to concatenate the files, and also add an additional column for “Year” or whatever since this was previously only in the file name. Please just provide a single file with all the data, this then avoids the extra horror of some files having different internal structures.
- Non UTF-8 character encoding. Usually this only gets reported when there are non-latin characters involved. Just use UTF-8 please.
- Introductory text before the header row. Ugh, don’t do this. How is a machine supposed to know when you’re done with your preamble? Notes about the quality of this dataset are essential, but they are meta-data and should live alongside the dataset, not in it.
- Non-normalised fields (number of columns is variable) If you’ve got columns in your spreadsheet for each year (2010, 2011, 2012 etc..) then please stop it, have a single “year” column and a separate column for the value. If you’ve got two rows of headers where you nest field names then you’ve got the same type of problem, only worse.
- Duplicate misspelt / mis-capitalised category terms. This tends to show up when you visualise, you’ll see a bar chart with bars labelled “SaaS Services”, “SaaS”, “SAAS”, etc…
- Empty cells (nulls) where there should be a value. Perhaps the most egregious and hard to spot issue, this indicates there is a problem with the accuracy and reliability of the data, but of course our spreadsheet doesn’t bat an eye.
All of these issues will necessitate some data clean-up. Sometimes this can be done in tools that the non-expert user has like Microsoft Excel, sometimes they need some code written in order to be solved. Most of these issues can be overcome with the excellent OpenRefine software.
What can we do to improve machine readability?
I have in the past been a big supporter of RDF linked data. After spending a significant portion of my life waiting for SPARQL queries to execute, I came to accept that passing around data in a CSV file is not such a bad thing. They’re simple, it’s an open format, and we’re already using them, so CSV it is. Unless of course it’s geo-data or something that is much easier consumed and transferred in some other format.
Now, what about enforcing a schema on the internal structure of the CSV file? Some great work has already been done here, it just needs to be adopted and applied. The best option seems to be csvlint.io as it builds on previous work that was done in JSON Table Schema (part of datapackage.json), CSV Schema (by the National Archives team), and supports the W3C CSV on the Web group’s Tabular Data Primer. All of these tools describe the csv structure (e.g. single header row containing field names) and allow you to place some constraints on the row data for each field (e.g. type checking).
Csvlint will not only check for a consistent internal schema, but will check that the file has UTF-8 character encoding, CRLF line breaks and other less forgivable transgressions such as ragged rows.
What about the problem of duplicate misspelt terms that need to be grouped together? Well, registers might be able to help us here, if the terms are part of one. Registers are canonical lists of things — for example companies, buildings, hospitals, schools etc. I see nothing wrong with taking a ghetto linked-data approach here, and putting an identifier to entities that exist in a register in our dataset’s CSV file. Csvlint could then accept the register as a “type” so that it can check the integrity of what is in relational database terms — a foreign key.
What about all the other data quality issues we mentioned at the beginning? Well, ODI certificates are pretty good at covering those. So we just need registers with identifiers we can link to (bear in mind the contents of these registers may be different at any point in time), csvlint to check linking to registers, ODI certificates to incorporate csvlint and then for publishers to actually use all this stuff. Hmm…
Why bother?
Because open data is supposed to be used by citizens, not just businesses, and the way it’s currently published means that getting answers from open data is out of reach to most people. Should it be left up to private companies to make open data accessible to citizens?
This Code is issued to meet the Government’s desire to place more power into citizens’ hands to increase democratic accountability and make it easier for local people to contribute to the local decision making process and help shape public services.
There is also a lot of duplication of effort happening at the moment. We’re all spending hours cleaning up and transforming datasets and there is no good way to share the outcome of this work. This work is fragile and needs to be maintained if it is to keep working for future releases. Better we get it right at source.
Ideally our small business owner from the example above would go to data.gov.uk (where, incidentally, this G-Cloud dataset isn’t currently available) and from their search they’d get an interactive view of the data that can be explored, alongside any metadata and notes they need to interpret it. It is not only possible, but quite trivial, to produce automated visualisations for many of our open datasets, as long as they are machine readable.
We talk about data as infrastructure, and the open data community encourages companies to build products based on open data. That’s great, but these products need to really add value, not just clean up the data and make it useable by ordinary people, that is something we should expect of the data publishers and the publishing eco-system.
The good news is that we already have the technology we need to make this happen, and open data would be open to millions more people if we attacked the quality problem with the same effort and determination as we have done the quantity problem.